Aan de slag met lokale, privacyvriendelijke Large Language Models.
03.09.2024
Maak jij je ook zorgen over je privacy en ecologische voetafdruk als je ChatGPT om hulp vraagt? Dan zijn lokale LLM's (Large Language Modellen) misschien iets voor jou. In deze longread gaan we dieper in op wat lokale LLM's zijn, welke voor- en nadelen ze bieden en hoe jij er concreet mee aan de slag kan.
Wat zijn LLM's?
Een Large Language Model (LLM), in het Nederlands een ‘groot taalmodel’, is een geavanceerd type Artificiële Intelligentie. Meer specifiek vallen ze onder de AI-specialisatie van NLP (Natural Language Processing, ofwel Natuurlijke Taalverwerking in het Nederlands) alsook die van ‘Generatieve AI’. Deze modellen zijn ontwikkeld om menselijke taal te interpreteren en te genereren, ze kunnen worden gebruikt in toepassingen zoals chatbots, tekstgeneratie en vertalingen.
De bekendste, maar zeker niet de enige, LLM is ongetwijfeld ChatGPT van het bedrijf OpenAI. ChatGPT is wat we noemen een ‘cloud-based’ LLM, wat inhoudt dat je een internetverbinding nodig hebt om deze dienst te gebruiken. Als je ChatGPT een opdracht (of ‘prompt’) geeft om een bestaande tekst te interpreteren, samen te vatten of te herschrijven, wordt jouw invoer over het internet verstuurd naar de servers van OpenAI om daar verwerkt te worden.
Lokale LLM’s?
Nog relatief onbekend zijn de lokale LLM’s. In tegenstelling tot ‘cloud-based’ LLM’s hebben lokale LLM’s geen internetverbinding nodig bij gebruik. Je kan deze getrainde modellen namelijk downloaden en lokaal op jouw computer de nodige berekeningen laten uitvoeren. Hoe groter het aantal parameters (en dus berekeningen) dat het model doorloopt bij het uitvoeren van jouw opdracht, hoe groter de capaciteiten maar ook vereiste rekenkracht van het model. Grote modellen met tientallen miljarden parameters vereisen dan ook een krachtige computer (CPU en/of GPU) om vlot te functioneren. Daarom bieden populaire lokale LLM’s vaak modellen aan met meer of minder parameters. Hierover later meer.
Het verschil tussen open source- en open weights-modellen.
Een open-source LLM verwijst naar een LLM dat beschikbaar is gesteld onder een open-source licentie, zoals Apache 2.0 of MIT License. Dit betekent dat gebruikers toegang krijgen tot alle aspecten van het model, zoals de broncode, gewichten en (training)gegevens. Deze openheid ondersteunt een beter begrip van hoe het model functioneert, bevordert innovatie en moedigt ethisch onderzoek aan.
Een open-weight LLM verwijst daarentegen doorgaans naar een vooraf getraind taalmodel waarvan de gewichten (d.w.z. de getrainde parameters) openbaar zijn gemaakt, maar de onderliggende broncode of gegevens (bedrijfs)geheim blijven. Zo kunnen gebruikers het model toepassen en verfijnen voor specifieke taken, maar hebben ze beperkt inzicht in de innerlijke werking ervan.
Waarom zou je een lokale LLM wel of niet gebruiken?
Een lokale LLM gebruiken kan voordelen hebben:
1. Je privacy blijft behouden.
Een van de grootste zorgen bij het gebruik van commerciële cloud-LLM's is het risico op datalekken of ongeautoriseerde toegang tot gevoelige gegevens door de LLM-aanbieder. Jouw prompt aan ChatGPT wordt namelijk over het internet naar servers van OpenAI gestuurd om daar verwerkt te worden. Er zijn al verschillende controverses geweest over het potentiële gebruik van persoonlijke en vertrouwelijke gegevens als data voor het trainen ervan. OpenAI stelt zelf in hun FAQ dat jouw gebruikersdata gebruikt kan worden om het model te verbeteren, gedeeld kan worden met derde partijen en dat een selecte groep van geautoriseerde werknemers jouw data kunnen raadplegen. Door een lokale LLM te gebruiken, wordt deze informatie niet gedeeld of blijft ze binnen het computersysteem van jouw organisatie of bedrijf.
2. Je hebt geen internet nodig.
Eens je een LLM hebt geïnstalleerd, werkt deze volledig lokaal op je computer. Geen of beperkte toegang tot het internet? Geen probleem. Handig voor bijvoorbeeld de trein.
3. Je hebt de mogelijkheid om het taalmodel aan te passen.
Bij het gebruik van lokale LLM’s hebben gebruikers, afhankelijk of een model open source, dan wel open weight is, in meer of mindere mate toegang tot de werking van het model. Dit kan gaan van de trainingsdata en -gewichten tot de volledige broncode van het model. Deze transparantie is een eerste stap voor controle, maar geeft ook de mogelijkheid om het model aan te passen, bijvoorbeeld voor specifieke use-cases.
4. Je verbruikt minder energie en water.
Na de popularisering van LLM’s maken onderzoekers en milieuwaakhonden zich zorgen over de ecologische voetafdruk van de technologie. Cloud-LLM’s verbruiken niet enkel enorme hoeveelheden energie bij de trainen en het dagelijks gebruik van deze modellen, ook het waterverbruik voor het koelen en schoonmaken van deze enorme serverruimtes is niet te onderschatten. Daarbij publiceren commerciële aanbieders van cloud-LLM's zelden informatie over de middelen die nodig zijn om LLM’s te trainen en 24/7 te laten lopen, noch over de bijbehorende ecologische voetafdruk.
Door de eerder (in punt 3) aangehaalde transparantie van open source-modellen kunnen onderzoekers inzage krijgen over het energieverbruik en hebben ze de mogelijkheid om aanpassingen in het model te doen om deze efficiënter te maken en zo de ecologische voetafdruk te verkleinen.
Lokale LLM’s, zeker deze met relatief weinig parameters, werken op jouw eigen computer. Jouw prompts moeten dus niet naar de andere kant van de wereld verstuurd worden om daar op energiehongerige servers verwerkt te worden. Misschien goed om hier even bij stil te staan de volgende keer dat je “Hallo, hoe gaat het met je?” vraagt aan ChatGPT. 1
5. Je gebruik is gratis en onbeperkt.
De meeste commerciële cloud-LLM’s vereisen een betalend abonnement voor onbeperkt gebruik. Dit is niet het geval bij lokale LLM’s, omdat ze (in de meeste gevallen) gratis en onbeperkt te gebruiken zijn. 2
6. Een lokaal model presteert (bijna) even goed als een online model.
Grote varianten (>100B parameters) van lokale LLM’s van bekende techbedrijven zoals Meta en Google scoren vergelijkbaar met ChatGPT op gespecialiseerde tests en benchmarks. Maar ook de kleine(re) varianten (<10B parameters) volstaan voor de meeste dagelijkse thuis- en werk-prompts, zoals het samenvatten van teksten, het opstellen van e-mail drafts en om inspiratie op te doen of informatie op te vragen.
...maar een lokale LLM is niet altijd de beste keuze. Twee voorbeelden om rekening mee te houden:
1. Je hebt meer computerkennis nodig voor multimodaal gebruik.
De algoritmen van online LLM's zijn over het algemeen complexer en hebben toegang tot betere hardware (krachtige CPU’s en GPU’s). Ook is de functionaliteit ervan uitgebreider: recente cloud-LLM’s zijn ‘multimodal’, wat inhoudt dat ze verschillende soorten input en output kunnen verwerken en genereren, zoals tekst, audio en video. Zo kan je bijvoorbeeld een spreadsheet uploaden en vragen stellen over de data. Of een boekomslag laten genereren die past bij het verhaal dat je in volledigheid toevoegt in je prompt. Soortgelijke functionaliteiten zijn mogelijk met lokale modellen maar vereisen een bovengemiddelde computerkennis omdat de verschillende functionaliteiten vaak allemaal apart geïnstalleerd en gefinetuned moeten worden.
2. Je hebt er een (relatief) krachtige computer voor nodig.
Lokale LLM’s kunnen, afhankelijk van het aantal parameters dat ze gebruiken, een krachtige computer vereisen. Voor gebruik op een standaard laptop of computer (zonder krachtige CPU en/of GPU) raden we aan om een versie van LLM te gebruiken met minder dan 10B parameters. Deze modellen vereisten minder rekenkracht en hebben een kleinere bestandsgrootte.
- 1 Voor de volledigheid moet vermeld worden dat het trainen van alle LLM’s (ook lokale) nog steeds op servers uitgevoerd moet worden, door de enorme rekenkracht die hiervoor nodig is.
- 2 We spreken hier enkel over (kleinere) modellen die op jouw lokale computer draaien. Voor grote modellen volstaat de rekenkracht van een doorsnee thuiscomputer niet. Deze worden op servers in eigen beheer of van een cloud provider (zoals Amazon Web Services of Microsoft Azure) geïnstalleerd. De aankoop of huur van deze servers brengt natuurlijk een kost met zich mee. Op deze manier vergroot ook de ecologische voetafdruk. De voordelen i.v.m. privacy en transparantie blijven wel onveranderd.
Welke modellen bestaan er?
Het aantal vrij beschikbare LLM’s is virtueel onbeperkt. Iedereen (met de nodige kennis) kan namelijk aan de slag met het aanpassen en hertrainen van LLM Foundation Models.
We kiezen er drie modellen uit die elk specifieke kwaliteiten hebben:
- LLaMA
LLaMA (Large Language Model Application) is een LLM ontwikkeld door Meta AI, voorheen Facebook AI. Op het moment van schrijven is LLaMA3.1 de meest recente versie en beschikbaar in drie varianten: 8B, 70B of 405B parameters.
Update 26 september 2024: LLaMA3.2 is nu beschikbaar in 1B en 3B varianten. Deze modellen kunnen ook op minder krachtige computers gebruikt worden.
- GEMMA
GEMMA (Generalized Model for Multi-Modal Abstraction) is een LLM ontwikkeld door Google DeepMind. Het is een ‘open’ versie van Gemini, Google zijn rechtstreekse (commerciële) concurrent van ChatGPT. Op het moment van schrijven is GEMMA2 de meest recente versie en beschikbaar in twee varianten: 9B of 27B parameters.
- Phi
Phi is een SLM (Small Language model) ontwikkeld door Microsoft. Vergeleken met andere modellen bevat Phi beduidend minder parameters. Hierdoor vereist het model minder rekenkracht en is het beter geschikt om op laptops met lage(re) specificaties of zelfs mobiele apparaten te werken. Op het moment van schrijven is Phi-3 de meest recente versie en beschikbaar in twee varianten: Mini (3B parameters) of Medium (14B parameters).
Zoals eerder aangehaald: voor gebruik op een niet-gespecialiseerde laptop of computer raden we voor alle LLM’s een versie aan met minder dan 10B parameters. Deze modellen vereisten minder rekenkracht en hebben een kleinere bestandsgrootte.
Hoe ga je er zelf mee aan de slag?
Er zijn verschillende manieren om lokale modellen te gebruiken op je eigen computer. Zo kan je modellen integreren in verschillende IDE’s (programma’s om code te schrijven). Om zo gebruiksvriendelijk mogelijk te zijn en zo goed mogelijk de ChatGPT-ervaring te benaderen, geven we hieronder twee voorbeelden van applicaties waarmee je zelf modellen kan downloaden en lokaal op je computer mee kan converseren: 'Jan' en 'Ollama'
Optie 1: Jan
Beschikbaar op macOS, Windows en Linux
Voordelen:
- Gebruiksvriendelijk
- Mogelijkheid om verschillende model-parameters aan te passen alsook de optie om de LLM-assistent een basisinstructie mee te geven waarmee rekening gehouden wordt bij het beantwoorden van jouw prompts. Bijvoorbeeld: “Beantwoordt alle prompts in de rol van een leerkracht die lesgeeft in de basisschool.”. Dit zal ervoor zorgen dat de assistent bv eenvoudig taalgebruik en zinsbouw zal gebruiken.
Nadelen:
- Trager met nieuwe modellen beschikbaar te maken.
- Beperkter aanbod van modellen (die in het programma te downloaden zijn).
Installatie van Jan
- Stap 1: Surf naar https://jan.ai, download de versie die overeenkomt met jouw besturingssysteem (Mac, Windows of Linux) en installeer de software.
- Stap 2: Download en installeer een LLM naar keuze: Open Jan (het programma) en klik op het ‘Hub’-icoon (aangegeven met de rode pijl en cirkel in onderstaande afbeelding).

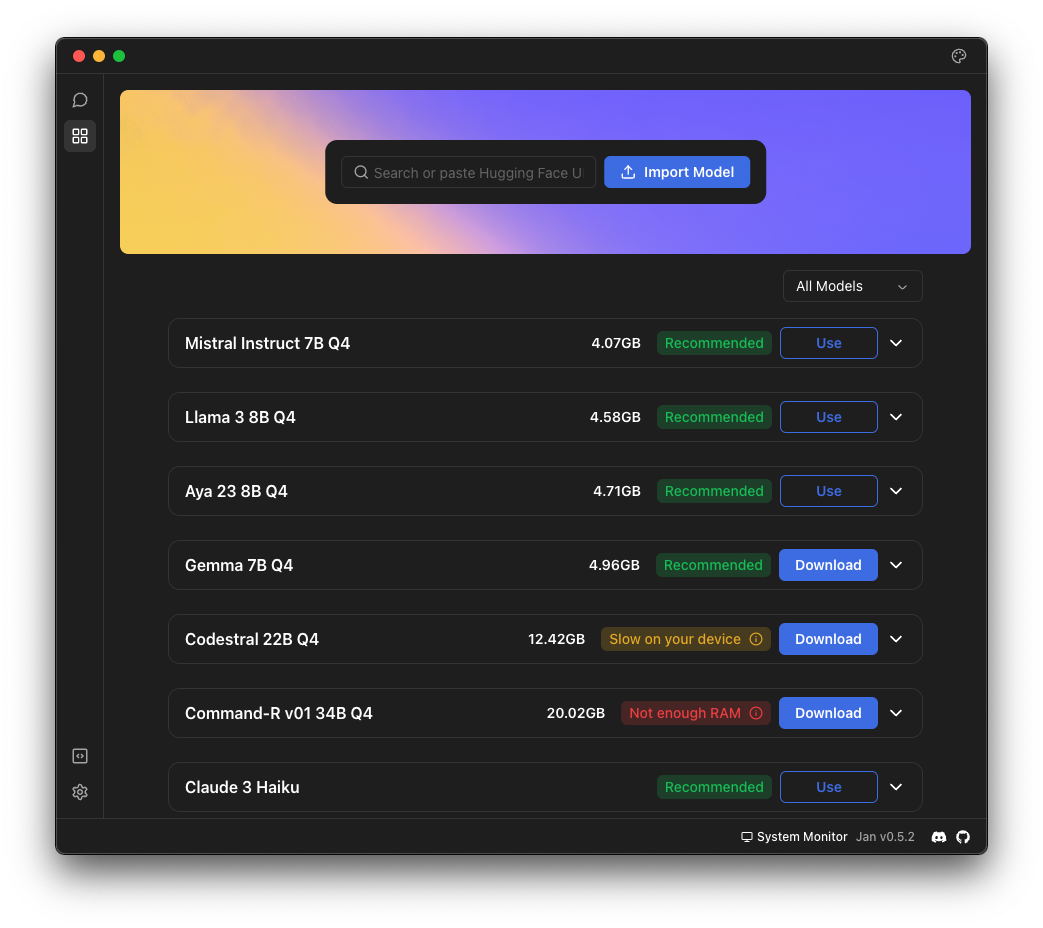
- Stap 3: Merk op dat het programma een lijst geeft van beschikbare modellen en of een model wel of niet geschikt is voor jouw computer (zie onderstaande afbeelding). Kies een model met het label ‘Recommended’ of (minimaal) ‘Slow on your device’ en download het. Het programma geeft je ook de (meer geavanceerde) optie om zelf een model te importeren.
- Stap 4: Klik terug op het ‘Tread’-icoontje (aangegeven met de rode pijl en cirkel op onderstaande afbeelding) om terug te keren naar het basisscherm. Klik vervolgens op ‘Model’ en selecteer een model dat je zonet gedownload hebt.
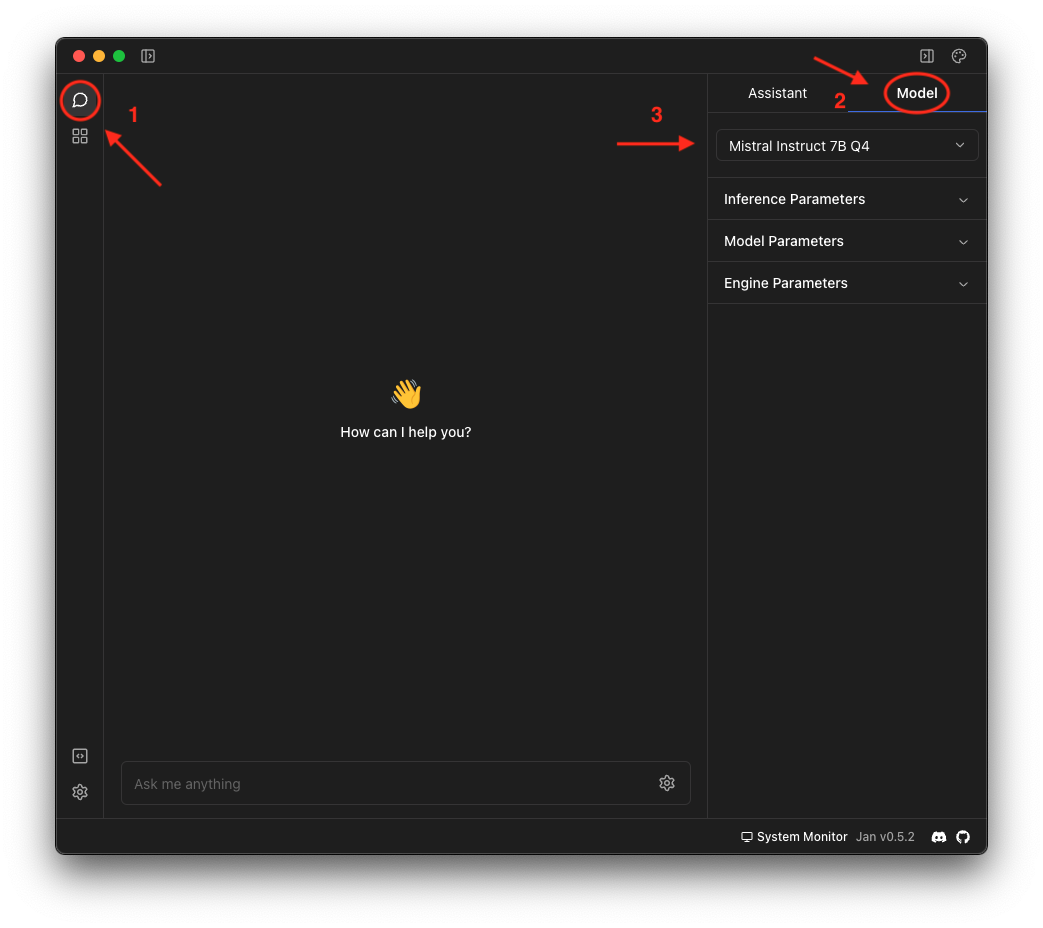
- Stap 5 (optioneel & geavanceerd): Pas de parameters aan naar jouw voorkeur en geef de assistent een basisinstructie.
- Stap 6: Geeft je vraag of prompt in, in het daarvoor bestemde tekstveld en druk op ‘enter’. Het LLM zal nu een antwoord formuleren, net als ChatGPT. De snelheid waarmee het dit doet hangt af van de complexiteit van je prompt en de rekenkracht van jouw computer.

Optie 2: Ollama
Beschikbaar op macOS, Linux en Windows (in preview versie).
Voordelen:
- Lightweight en efficiënt
- Nieuwe (populaire) modellen praktisch meteen beschikbaar.
Nadelen:
- De installatie kan wat omslachtig of intimiderend zijn voor personen die weinig of geen ervaring hebben om met ‘Terminal’ (Mac) of de ‘Command Prompt’ (Windows) te werken.
Installatie van Ollama
- Stap 1: Surf naar https://ollama.com, download de versie die overeenkomt met jouw besturingssysteem (Mac, Windows of Linux) en installeer de software.
- Stap 2: Open Ollama. Je zal zien dat er geen venster geopend wordt, dit is normaal. Als je goed kijkt kan je een llama-icoontje terugvinden in de rechterbovenhoek (Mac) of rechteronderhoek (Windows), dit wil zeggen dat Ollama op de achtergrond actief is.
- Stap 3: Bekijk de verschillende beschikbare modellen op https://ollama.com/library. Noteer de naam van het model dat je wil installeren.
- Stap 4: Open ‘Terminal’ of ‘Command Prompt’ op je computer en typ “ollama run *exacte modelnaam*”, waarbij *exacte modelnaam* vervangen wordt door de naam van je gekozen model. Om bijvoorbeeld GEMMA2 te downloaden en installeren typ “ollama run gemma2”. Je kan de verschillende versies van modellen apart installeren door ze te specifiëren in de modelnaam. Zie de model-pagina op de website van ollama voor meer info.
- Stap 5: Na installatie zal het model automatisch opstarten en krijg je de optie om in in de Terminal/Command Prompt applicatie zelf je vraag te stellen. Elke keer je de Terminal/Command Prompt-applicatie sluit en heropent moet je ook de LLM die je wil gebruiken opstarten met “ollama run *exacte modelnaam*”.
Extra:
Handige Ollama Terminal-prompts:
- Om een model op te starten:
Ollama run *model name*
- Om alle geïnstalleerde modellen te updaten naar de laatst beschikbare versie:
ollama list | awk 'NR>1 {print $1}' | xargs -I {} sh -c 'echo "Updating model: {}"; ollama pull {}; echo "--"' && echo "All models updated."
- Om een overzicht te krijgen van alle geïnstalleerde modellen:
ollama list
- Om meer informatie te krijgen over een bepaald geïnstalleerd model:
ollama show *model name*
- Om een geïnstalleerd model te verwijderen:
ollama rm *model name*
Optioneel (maar aangeraden) voor macOS gebruikers:
Er bestaan verschillende programmas om de functie van Ollama in een gebruiksvriendelijke GUI (Graphical User Interface, dus een gebruiksvriendelijke applicatie) te gebruiken. Wij selecteerden ‘Ollamac’ (niet te verwarren met Ollamac Pro). Ollamac is een gratis en open-source programma. Je kan het via deze GitHub-pagina downloaden voor macOS: https://github.com/kevinhermawan/Ollamac
ㅤ
