Met welke AVG-verplichtingen moet ik rekening houden bij de verwerking van persoonsgegevens voor wetenschappelijke of statistische doeleinden?
De verwerking van persoonsgegevens voor wetenschappelijke of statistische doeleinden valt onder het toepassingsgebied van de AVG. De AVG geeft de EU-lidstaten echter de mogelijkheid om in deze context uitzonderingen op bepaalde regels te voorzien. Deze fiche licht de alternatieve verplichtingen toe die gelden in België en die samen met de normale AVG-verlichtingen van toepassing zijn.
De fiche legt dus niet de algemene AVG-verplichtingen uit, maar focust op de specifieke Belgische regels voor wetenschappelijk of statistisch onderzoek (in een AI-context).
Wil je graag meer info over de algemene verplichtingen? Bekijk dan zeker de eerder uitgebrachte fiche, het rapport ‘Artificiële intelligentie en gegevensbescherming: een verkennende gids’ en toekomstige fiches.
FIRST THINGS FIRST: VOOR WAT EN WIE?
Alvorens de alternatieve verplichtingen toe te lichten … Wat begrijpt de AVG onder wetenschappelijk of statistisch onderzoek?
- Wetenschappelijk onderzoek wordt ruim opgevat. Het omvat bijvoorbeeld technologische ontwikkeling en demonstratie, fundamenteel onderzoek, toegepast onderzoek en uit private middelen gefinancierd onderzoek. Het (her)trainen van een AI-systeem tijdens de ontwikkelingsfase, maar niet tijdens de gebruiksfase, kan hieronder vallen. Dit geldt ook voor fundamenteel AI-onderzoek (bv. het opstellen van algoritmes), ongeacht of er sprake is van private of publieke financiering.
- Onder statistische doeleinden wordt verstaan: het verzamelen en verwerken van persoonsgegevens die nodig zijn voor statistische onderzoeken en voor het produceren van statistische resultaten. Cruciaal is hier dat het onderzoek met een statistisch oogmerk gebeurt. Dit betekent dat het resultaat van de verwerking voor statistische doeleinden niet uit persoonsgegevens, maar uit geaggregeerde gegevens moet bestaan. Dit resultaat en de gerelateerde persoonsgegevens mogen daarbij geen aanleiding geven tot maatregelen of beslissingen die een specifieke natuurlijke persoon betreffen (omgekeerd, wel een groep personen). In een AI-context kan er gedacht worden aan gebruik(er)statistieken of accuraatheidsanalyses van de technologie zowel tijdens de trainings- als de implementatiefase.
Kortom, indien je werkt voor een private of publieke organisatie, al dan niet met een winstoogmerk, die wetenschappelijk of statistisch onderzoek verricht en daarbij persoonsgegevens verwerkt, dan is deze fiche iets voor jou.
Hou niettemin rekening met het feit dat de inhoud van deze fiche
mogelijk minder rechttoe rechtaan toe te passen is dan het op het eerste
zicht kan lijken. Het is daarom belangrijk om altijd met het gezond verstand
na te denken over de verwerking van persoonsgegevens. Doe daarom het volgende gedachte-experiment: zou jij het als onderzoeker logisch of aanvaardbaar vinden als jouw eigen
persoonsgegevens zouden worden verwerkt op de door jouw voorziene manier
of door de door jouw gekozen derde partij? Hou ook rekening met de in
jouw organisatie geldende gegevensbeschermingsrichtlijnen en contacteer bij vragen de verantwoordelijke voor gegevensbescherming of DPO, indien aangesteld.
WAT BESPREKEN WE IN DIT ARTIKEL?
Ter illustratie van de Belgische uitzonderingsregels, doorlopen we een scenario dat grofweg chronologisch parallel loopt aan een normaal verloop van een wetenschappelijk of statistisch onderzoek, namelijk:
- De verzameling van persoonsgegevens;
- De onderzoeksfase;
- En tot slot, de rapporteringsfase.
Per fase, geven we enkele actiepunten waarmee je dient rekening te houden onder de in deze fiche toegelichte regels.
Indien beschikbaar, raden we je aan om onderstaande documenten bij elkaar te zoeken, zodat je de inhoud van deze fiche ten volle kan benutten:
- Contactgegevens van de verantwoordelijke voor gegevensbescherming of DPO van jouw organisatie. Contacteer deze persoon alvorens je verder gaat met de fiche of andere documenten zoekt.
- Het register van verwerkingsactiviteiten van jouw organisatie.
- Externe privacyverklaring van jouw organisatie.
- Een sjabloon voor een Data Protection Impact Assessment (DPIA).
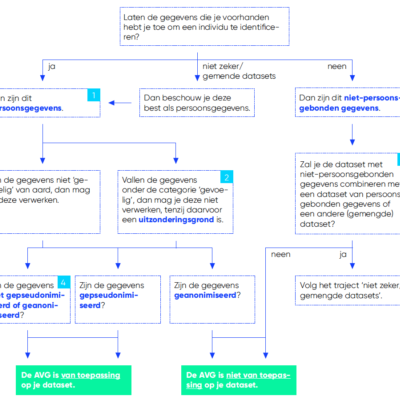
Ben je niet zeker of de door jou verwerkte gegevens onderworpen zijn aan de AVG, of wens je meer uitleg over het verschil tussen gepseudonimiseerde en geanonimiseeerde persoonsgegevens? Neem dan zeker onze eerste fiche door die je daarbij helpt.
Verzameling van persoonsgegevens
Geert verricht onderzoek aan een Vlaams onderzoekscentrum naar het gebruik van AI in rekrutering. Hij ontwerpt en verbetert de daarbij gebruikte algoritmes. Om (de nauwkeurigheid van) een algoritme te testen, vraagt hij een groep vrijwilligers om hun CV in te dienen voor een fictieve vacature. Dit gebeurt via een online invulformulier. De CV’s worden geanalyseerd door een software die gebruik maakt van Geert’s algoritme en iedere CV een score toekent. Deze score geeft weer in welke mate een kandidaat geschikt is voor de vacature. Ter controle van zijn resultaten, vraagt Geert aan Fatima, een collega-onderzoekster, een gelijkaardige set gegevens (CV’s). Zij overhandigt hem deze gegevens, die stammen uit een ander onderzoeksproject, via een externe harde schijf. Geert zal trouwens bijkomende, publiek beschikbare informatie opzoeken over zijn respondenten op hun sociale media (bv. LinkedIn of Facebook).
ACTIEPUNTEN:
Geert verzamelt zowel rechtstreeks bij zijn respondenten (via het invulformulier) als onrechtstreeks (via Fatima en sociale media) persoonsgegevens.
Rechtstreekse gegevensverzameling
In geval van rechtstreekse gegevensverzameling moet Geert bepaalde informatie toevoegen aan de privacyverklaring die hij aan zijn respondenten bezorgt vooraleer zij het formulier invullen. Deze informatie komt dus bovenop de informatie die moet worden meegedeeld volgens artikel 13 AVG. Meer bepaald moeten de betrokkenen geïnformeerd worden over de volgende twee aspecten:
- het feit of hun gegevens al dan niet worden geanonimiseerd;
- de eventuele redenen volgens dewelke de uitoefening van de rechten van de betrokkenen de verwezenlijking van de onderzoeksdoeleinden onmogelijk dreigen te maken of ernstig dreigen te belemmeren, m.a.w. waarom de rechten die betrokkenen onder de AVG genieten de doeleinden van het onderzoek negatief kunnen beïnvloeden (zoals het onderzoek onmogelijk maken, of ernstig belemmeren).
Onrechtstreekse gegevensverzameling
In geval van onrechtstreekse gegevensverzameling moet Geert in principe een overeenkomst sluiten met de oorspronkelijke verwerkingsverantwoordelijke(n). Indien de gegevens echter publiek werden gemaakt, dient Geert enkel een kennisgeving te richten aan die oorspronkelijke verwerkings-verantwoordelijke(n). In dit geval moet Geert dus een overeenkomst sluiten met de organisatie van Fatima en een kennisgeving richten aan de betrokken sociale media-platformen.
Deze overeenkomst of kennisgeving moet minstens de volgende elementen bevatten:
- in geval van een overeenkomst, de contactgegevens van de verantwoordelijke voor de oorspronkelijke verwerking (nl. Fatima/haar instelling) en van de verantwoordelijke voor de verdere verwerking (nl. Geert/zijn onderzoekscentrum);
- Indien van toepassing, de redenen volgens dewelke de uitoefening van de rechten van de betrokkene de verwezenlijking van de onderzoeksdoeleinden onmogelijk dreigen te maken of ernstig dreigen te belemmeren.
Indien een partij als verwerkingsverantwoordelijke en de andere als verwerker zou optreden (bv. in de hypothese dat Geert onderzoek zou verrichten op instructie van Fatima), dient er een verwerkersovereenkomst te worden gesloten conform artikel 28 AVG. Wil je meer weten over de rol van verwerkingsverantwoordelijke en verwerker? Bekijk dan even deze eerder uitgebrachte fiche.
Belangrijk is dus dat Geert (zijn onderzoekscentrum), voorafgaand aan de verzameling van de gegevens, volgende zaken overweegt:
- in welke mate de (mogelijke) uitoefening door betrokkenen van hun rechten onder de AVG, de verwezenlijking van zijn specifieke wetenschappelijke of statistische onderzoeksdoeleinden onmogelijk dreigt te maken of ernstig dreigt te belemmeren; en
- in welke mate het beperkt of niet (hoeven) antwoorden op dergelijke verzoeken noodzakelijk is om de doeleinden te bereiken.
De uitkomst van deze afweging moet worden toegevoegd aan de bovenvermelde privacyverklaring, overeenkomst en kennisgeving. Daarenboven moet er ook gerelateerde bijkomende informatie worden toegevoegd aan het register van verwerkingsactiviteiten van Geert’s onderzoeksinstelling. Deze bijkomende elementen zijn:
- de verantwoording van het gebruik van al dan niet gepseudonimiseerde gegevens;
- de redenen waarom de uitoefening door betrokkenen van hun rechten de verwezenlijking van de onderzoeksdoeleinden onmogelijk dreigt te maken of ernstig dreigt te belemmeren;
- desgevallend, de Data Protection Impact Assessment (DPIA) indien de verwerkingsverantwoordelijke gevoelige gegevens voor wetenschappelijke of statistische doeleinden verwerkt.
Wat moet je echter doen als jouw organisatie reeds relevante gegevens bezit? Bepaal dan eerst of dergelijke ‘gerecycleerde’ persoonsgegevens wel degelijk verder zullen worden verwerkt (dus na of los van de initiële verwerking) voor een wetenschappelijk of statistisch onderzoeksdoeleinde. Zo ja, informeer dan de betrokkenen over die verdere verwerking vooraleer je effectief overgaat tot de verwerking (tenzij er sprake is van een van de uitzonderingsgevallen (zie art. 14.5 (b) AVG).
Wetenschappelijk of statistisch onderzoek
Geert gebruikt dus zowel gegevens die hij zelf verzamelde (via het invulformulier) als gegevens die hij via derden heeft verkregen (via Fatima en sociale media). Hij denkt deze gegevens zeker twee maanden nodig te hebben, maar kan niet uitsluiten dat zijn onderzoek wat meer tijd gaat kosten. Mogelijk wil hij deze gegevens ook hergebruiken voor een later onderzoek.
ACTIEPUNTEN:
Bij de verwerking van persoonsgegevens voor wetenschappelijke of statistische doeleinden is in België een ‘waterval’-systeem van toepassing. In principe moet Geert zijn onderzoek voeren met geanonimiseerde gegevens. Indien Geert zijn onderzoeksdoel niet kan bereiken met anonieme gegevens, mag hij gepseudonimiseerde persoonsgegevens gebruiken (in de eerste fiche wordt dit begrip toegelicht). Indien hij zijn onderzoeksdoel ook niet kan bereiken met gepseudonimiseerde gegevens, mag hij niet-gepseudonimiseerde/ identificerende persoonsgegevens gebruiken. Let op, indien hij gegevens anonimiseert, is op de daaropvolgende verwerking de AVG niet meer van toepassing!
Geert dient daarbij rekening te houden met de Belgische regels die bepalen wanneer en hoe gegevens geanonimiseerd of gepseudonimiseerd moeten worden. Afhankelijk van de situatie waarin men zich bevindt, dient namelijk de oorspronkelijke verwerkingsverantwoordelijke dan wel een derde vertrouwenspersoon de (doorgegeven) persoonsgegevens op een bepaald moment te anonimiseren of te pseudonimiseren. Geert dient dus te bepalen in welke van de volgende vier, wettelijk beschreven, situaties hij zich bevindt.
- Situatie 1: indien het gaat over een rechtstreekse gegevensverzameling bij de betrokkene, dient de verwerkingsverantwoordelijke over te gaan tot de anonimisering of pseudonimisering van de gegevens na
de verzameling ervan.
- Deze situatie is van toepassing voor de gegevens die Geert verzamelt via het invulformulier. Daarenboven pseudo- of anonimiseert Geert ook best de gegevens die hij verzamelt via sociale media.
- Situatie 2: indien de verwerkingsverantwoordelijke reeds persoonsgegevens in zijn bezit heeft (ingevolge een eerdere verwerking) en die zelf wil verwerken met het oog op wetenschappelijke of statistische doeleinden, anonimiseert of pseudonimiseert de verwerkingsverantwoordelijke de gegevens voorafgaand
aan de verdere verwerking. De verwerkingsverantwoordelijke mag deze persoonsgegevens slechts de-pseudonimiseren indien dat noodzakelijk is voor het onderzoek, en desgevallend na advies van de Data Protection Officer, wat goed bijgehouden moet worden.
- Deze situatie zal van toepassing zijn wanneer Geert de set gegevens hergebruikt in een later onderzoek en de gegevens nog niet eerder werden geano- of pseudonimiseerd.
- Situatie 3: indien een verwerkingsverantwoordelijke de persoonsgegevens doorgeeft aan een andere verwerkingsverantwoordelijke, pseudonimiseert of anonimiseert de oorspronkelijke verwerkingsverantwoordelijke de gegevens voorafgaand aan de mededeling ervan aan de verantwoordelijke voor de verdere verwerking. De verantwoordelijke voor de verdere verwerking mag geen toegang tot de sleutels van de pseudonimisering hebben.
- Deze situatie is van toepassing voor de gegevens die Fatima doorgeeft aan Geert. Zij moet deze gegevens dus gepseudo-of geanonimiseerd opladen op de externe harde schijf alvorens deze te bezorgen aan Geert (tenzij Geert identificerende persoonsgegevens zou nodig hebben voor het bereiken van zijn onderzoeksdoel).
- Situatie 4: indien er meerdere oorspronkelijke verwerkingen worden gekoppeld, laten de oorspronkelijke verwerkingsverantwoordelijken voorafgaand aan de mededeling van de gegevens aan de verantwoordelijke voor de verdere verwerking, de gegevens anonimiseren of pseudonimiseren door één van de verantwoordelijken voor de oorspronkelijke verwerking of door een derde vertrouwenspersoon. Indien een van de oorspronkelijke verwerkingsverantwoordelijke gevoelige gegevens doorgeeft in een dergelijke situatie, mag enkel deze verwerkingsverantwoordelijke, voorafgaandelijk aan de mededeling van de gegevens aan de verdere verwerkingsverantwoordelijke, de gegevens anonimiseren of pseudonimiseren (of een derde vertrouwenspersoon). Enkel de verantwoordelijke voor de oorspronkelijke verwerking die de gegevens heeft gepseudonimiseerd of de derde vertrouwenspersoon mogen toegang hebben tot de pseudonimiseringssleutels.
- Deze situatie is niet van toepassing in het geval van Geert.
Tot slot moet Geert ook bepalen of het handig zou zijn dat hij de persoonsgegevens langer dan de strikt noodzakelijke periode kan bewaren, mits deze gegevens louter (verder) zouden worden verwerkt voor wetenschappelijk onderzoek of statistische doeleinden. Aangezien Geert deze gegevens eventueel later wenst te hergebruiken in een onderzoek, zal hij de gegevens langer willen bewaren. Daartoe moet hij passende technische en organisatorische maatregelen voorzien (zoals toegangs- en gebruiksbeperkingen).
Rapportering over onderzoek
Zodra Geerts’ onderzoek is voltooid, wilt hij er graag een paper over publiceren. Net zoals Fatima haar gegevens heeft doorgegeven aan Geert, wil hij de verzamelde CV-gegevens ook publiek beschikbaar maken op zijn website zodat andere onderzoekers zijn onderzoek kunnen verifiëren.
ACTIEPUNTEN:
Geert wil de door hem verzamelde persoonsgegeven zowel in paper-vorm als online publiek bekend maken. Dit valt onder de zogenaamde ‘verspreiding van gegevens’. Geert moet hierbij rekening houden dat hij geen identificerende/niet-gepseudonimiseerde gegevens mag verspreiden tenzij hij zeker is dat één van de volgende uitzonderingen van toepassing is:
- de respondent heeft zijn toestemming tot dergelijke verspreiding verleend; of
- de gegevens zijn door de respondent zelf openbaar gemaakt (bv. via sociale media); of
- de gegevens hangen nauw samen met het openbare of historische karakter van de respondent; of
- de gegevens hangen nauw samen met het openbare of historische karakter van feiten waarbij de respondent betrokken was.
Geert mag wel gepseudonimiseerde gegevens verspreiden tenzij specifieke wetgeving dit niet toelaat of indien het gaat over gevoelige gegevens (bv. medische gegevens, zie artikel 9 AVG. Geanonimiseerde gegevens mogen altijd worden verspreid.
Fatima heeft op haar beurt een ‘mededeling van gegevens’ aan een geïdentificeerde derde (nl. Geert) gedaan door hem de externe harde schijf te bezorgen. Identificerende/niet-gepseudonimiseerde persoonsgegevens mogen worden doorgeven voor wetenschappelijke of statistische doeleinden aan een geïdentificeerde derde. In drie gevallen mogen de gegevens echter niet reproduceerbaar zijn door de verdere verwerker, tenzij op handgeschreven wijze (dus pen en papier), nl.:
- indien het om gevoelige persoonsgegevens gaat; of
- de overeenkomst tussen de verantwoordelijken voor de oorspronkelijke verwerking en de verdere verwerking dit verbiedt (zie eerder); of
- die reproductie de veiligheid van de betrokkene in het gedrang kan brengen.
In de hypothese dat de set gegevens van Fatima ook medische gegevens bevat en Geert identificerende/niet-gepseudonimiseerde persoonsgegevens zou nodig hebben voor zijn onderzoeksdoel, dan moet zij ervoor zorgen dat Geert deze medische gegevens niet kan reproduceren. Dat kan bijvoorbeeld door Geert een “enkel lezen”-toegang te geven. (Indien zij gepseudo- of geanonimiseerde gegevens doorgeeft (zie eerder), is deze verplichting niet van toepassing.)
Deze verplichting tot het niet reproduceerbaar maken van gegevens is echter niet van toepassing indien:
- de respondent zijn toestemming tot dergelijke mededeling heeft verleend; of
- de gegevens door de respondent zelf openbaar zijn gemaakt (bv. via sociale media); of
- de gegevens nauw samenhangen met het openbare of historische karakter van de respondent; of
- de gegevens nauw samenhangen met het openbare of historische karakter van feiten waarbij de respondent betrokken was.
Deze fiche is de tweede in een reeks van fiches die worden opgemaakt door het Kenniscentrum Data &
Maatschappij. De fiches bieden concrete en praktische tools/informatie aan op basis van de publicatie
'Artificiële Intelligentie en gegevensbescherming: een verkennende
gids'.
Deze fiche is verkrijgbaar onder een CC BY 4.0 licentie.